Opened 5 years ago
Closed 5 years ago
#5228 closed defect (fixed)
Blastprotein: Visual fixes
| Reported by: | Zach Pearson | Owned by: | Zach Pearson |
|---|---|---|---|
| Priority: | high | Milestone: | |
| Component: | UI | Version: | |
| Keywords: | Cc: | Eric Pettersen, Elaine Meng | |
| Blocked By: | Blocking: | ||
| Notify when closed: | Platform: | all | |
| Project: | ChimeraX |
Description (last modified by )
Paraphrased from Elaine's email:
1) Make buttons more like other dialog: i.e. get rid of "Blast" button and instead have Help, Apply (run calculation and keep dialog up), Reset (reset to initial default parameters), Close (dismiss), OK (run calculation and dismiss). See for example Hbonds (in menu under Tools... Structure Analysis).
(1a) Title bar should say "Blast Protein" instead of "Blastprotein"
(1b) Default matrix is wrong, should be BLOSUM62 not BLOSUM45
(2) title bar should say "Blast Protein Results" instead of "BlastProtein Results" (i.e. just insert a space).
(2b) Seems like the default name for the search is None, so one can end up with multiple results panels all with the same name. Is that a problem? (e.g. for sessions?) Maybe the default name should be automatically based on the query, e.g. set to the uniprot ID or structure-chain spec or first N chars of raw sequence, or sequential (bp1, bp1, bp3 ...)
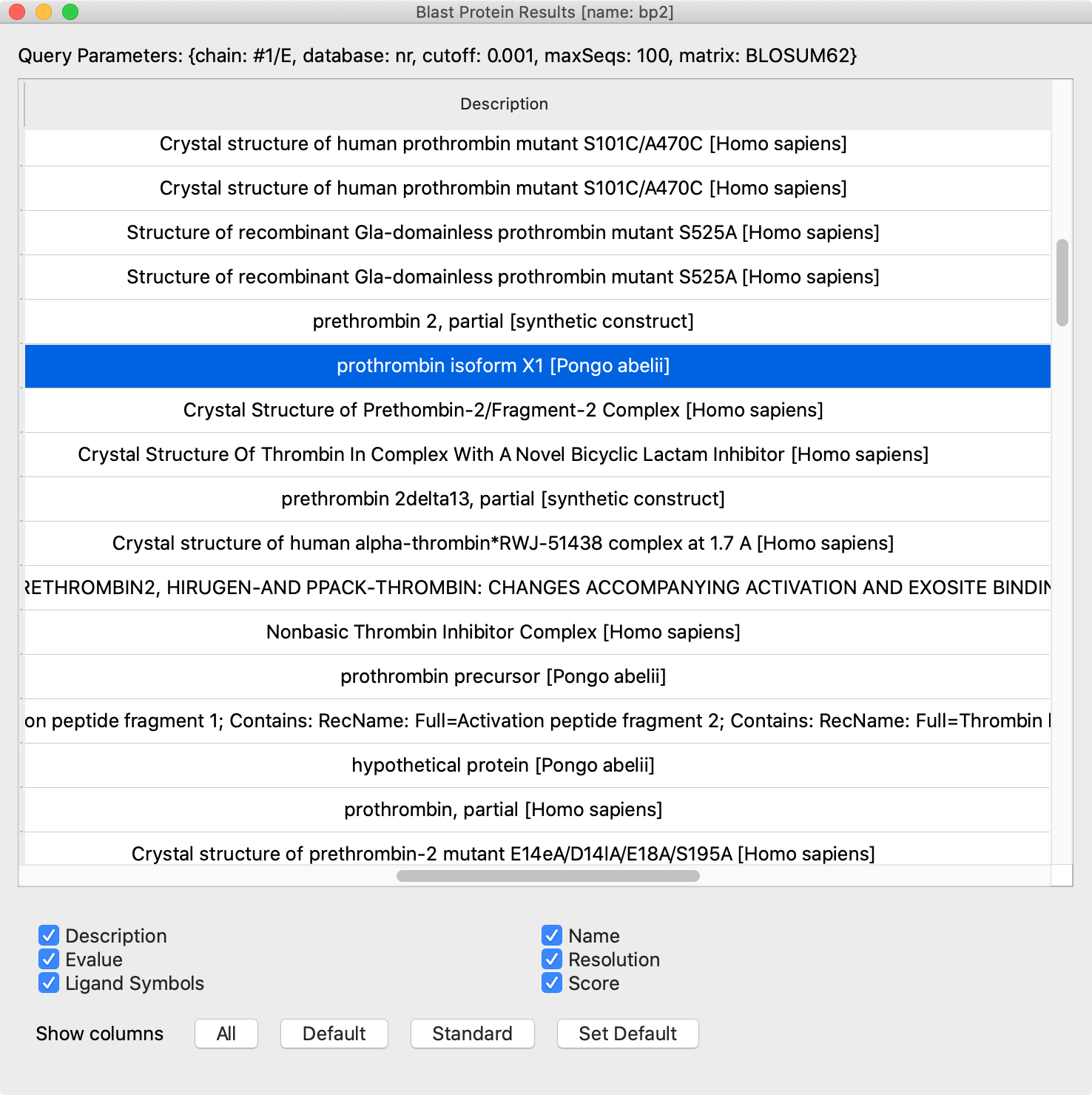
(3) Initial sort order should be highest to lowest score. I was surprised to see it was not in this order. Do you need Score to be shown in the table to sort on it? If so, add it to the suggested default columns in #6 below, next to Evalue.
(4) There is some "processing hits 0/N" line at the bottom that seems to be taking space for no reason. I've never seen it say anything other than 0/N. What processing? maybe it's non-0 at some point but should be removed when it's no longer showing any progress.
(5a) More column name tweaks.
Replace all "Num" and "Nr" with "#" (or at least "Num Polymers" -> "Nr polymers" so they're consistent)
Chain Species -> Species
(5b)
See also #6, column width. Where the widest thing in the column is the header, maybe we can make it shorter, e.g.
Resolution -> Resln
See also below, if we get rid of some of the column choices, that allows further simplification.
(6) Default columns. We definitely don't want ALL of the checkboxes turned on by default. Also is it possible to control the left-to-right-order of columns? I recommend the following:
=-=-=-=-=-=
For AlphaFold, defaults (and left-to-right order):
Name
Evalue
[Score, if we need it for sorting]
Description
Often some of the column values (Title, Species, ...) are blank but can be discerned from the Description value. The contents of Chain Sequence ID are inconsistent and perhaps that column should be nuked (for AlphaFold searches only, I mean). See ticket #5216. Sometimes the same hit is listed multiple times, #5217.
=-=-=-=-=-=
For PDB/NR, defaults in the order:
Name
Evalue
[Score, if we need it for sorting]
Description
Resolution
Ligand Symbols
Several hits are missing Structure ID even though it is obvious from Name what they should be. But I favor nuking the Structure ID column anyway.
For PDB searches, Chain Sequence ID is a UniProt identifier so I suggest renaming that column UniProt. For AlphaFold searches, above and in #5216 I suggested nuking Chain Sequence ID... if that doesn't conflict with the PDB suggestion for this column.
In Chimera, we offered fewer columns than those I see the current ChimeraX dialog. I lean toward paring down the ChimeraX choices similarly, which would allow simplifying some headers. E.g.
- Date – structure deposition date (thus omitting Revision Date and Publish Date)
- Authors – structure authors (thus omitting Citation Authors)
- PubMed – PubMed identifier of literature reference, if any
- UniProt – UniProt identifier, if any, for hit chain (this is currently called Chain Sequence ID)
Others I consider nukable are Replaces, Status, and Structure ID (as mentioned above, is obvious from Name).
(7) Column widths. Initial width should be based on widest item, but needs to be capped to some maximum (although the user should be able to adjust manually to wider later) and the text should wrap instead of showing an ellipsis. Typically there very long values in several different columns (Title, Description, Species, Ligand Name, etc.) so the simplest would be a single max for all, or if it's not a nightmare, perhaps a somewhat larger cap for Title and Description than for the others. Eric can probably help with that.
(8) I'm thinking maybe the results list should be above the columns for all the checkboxes. The checkboxes section could be shown/hidden with a Columns button like in Chimera (Zach probably you should try the Chimera one). Also would be nice if somebody could save their checkbox configuration as a preference, another thing that Eric can probably help with.
Attachments (5)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Change History (40)
comment:2 by , 5 years ago
| Description: | modified (diff) |
|---|
comment:3 by , 5 years ago
4: Should either update the progress bar to move as data is added to the hit sequences -- where it can make the most impact right now -- or refactor it or remove it altogether.
comment:4 by , 5 years ago
| Cc: | added |
|---|
In the notes of the initializer of ItemTable in https://github.com/RBVI/ChimeraX/blob/69bcb3ed8957507a8f1c7d74a46f328cc9e0d1e5/src/bundles/ui/src/widgets/item_table.py:
We promise consumers that they can specify a boolean for whether columns should be shown or hidden by default if they're not in a dictionary of default columns that should always be shown.
But later on in the code in ItemTable.add_column, it looks like we check the settings object we pass in for what to do instead of the dictionary we asked for.
Do you think it's safe to change it, Eric?
comment:5 by , 5 years ago
| Cc: | added |
|---|
The "fallback default" is for columns dynamically added to a table, i.e. ones whose existence you can't know about beforehand. That isn't the case with the Blast Results table. Your proposed code change would disable the user's ability to save their own default set of columns (well, to have that saved default have any effect).
What is the problem you are trying to solve here?
comment:6 by , 5 years ago
When I give the ItemTable a dict of default columns and set the fallback to false, it seems to want to display all the columns anyway.
follow-up: 9 comment:7 by , 5 years ago
The values in the dict should be True for columns you want displayed by default and False for columns you want hidden by default. 'fallback' shouldn't come into play at all since all your columns should be listed in that dict. Like I mentioned before, 'fallback' is for columns created on the fly where you cannot know ahead of time the columns name because it comes from runtime data or from the user, etc.
Assuming all your columns _are_ listed correctly in the dict, what happens when you click on the Default button? That is supposed to show the default set of columns.
follow-up: 8 comment:8 by , 5 years ago
Some revisions to my earlier opinions: (1) initial sort order should be smallest E-value to highest E-value. I thought this was always the same as highest score to lowest score, so I'd suggested that as the initial order, but apparently it is not exactly the same order. (2) if you do improve parsing to populate Species, etc. when the info is in the Description field but those columns (Species, etc.) are blank, then later (could be after release 1.3) we could revisit which should be the initial default columns. My initial recommendations of initial default columns were under the assumption that Species, etc. might be blank for a significant proportion of hits, and those recommendations are good enough for 1.3. (3) I thought of one case where the E-value rank (formerly ID column now nuked) might conceivably be useful: when somebody wants the top N hits in an alignment, it's hard to figure out if you're at row N when trying to select that many hits. I still lean toward not wasting the column space, but I'm open to going back to including it (but renamed something other than ID, say Rank) depending on any feedback from others.
comment:9 by , 5 years ago
Replying to Eric Pettersen:
The values in the dict should be True for columns you want displayed by default and False for columns you want hidden by default. 'fallback' shouldn't come into play at all since all your columns should be listed in that dict. Like I mentioned before, 'fallback' is for columns created on the fly where you cannot know ahead of time the columns name because it comes from runtime data or from the user, etc.
Assuming all your columns _are_ listed correctly in the dict, what happens when you click on the Default button? That is supposed to show the default set of columns.
I have to click the button a couple of times, see #5307, but the non-default columns get hidden. It's just that when they're first displayed, they're _all_ displayed.
comment:11 by , 5 years ago
For AlphaFold, the set of columns looking very good in today's build. The only additional recommendations for AlphaFold columns are to add a Rank column, include it on the far left in the standard set of columns, and rename the Chain Species column to Species.
For PDB/NR/UnirefN I'll have to re-evaluate the set of columns after seeing what it looks like after the disappeared ones come back.
Other "visual" things I can see still need doing are limiting column width and wrapping text within, and debloating the blank space of the dialogs (both input and results) as suggested by Eric.
comment:12 by , 5 years ago
Another recommendation is to parse the PDB/NR results Description field into Title and Species, similar to what you did with Alphafold results. For both structure hits and sequence-only hits, as far as I can tell, the Description is basically a title but with the species in square brackets at the end. See attachment "nrdescription 2021-09-29.png" ... some of them have "synthetic construct" in the square brackets but I think that would be OK to put in the Species field.
follow-up: 13 comment:14 by , 5 years ago
The set of columns I had in mind are in this documentation preview (not yet committed/pushed): https://www.cgl.ucsf.edu/home/meng/chimerax/vdocs/user/tools/blastprotein.html#results
follow-up: 14 comment:15 by , 5 years ago
I spun off 5b and comment 12 into new tickets, and I think I've fixed most of the other things in this ticket. I think it's good enough to take the 1.3 tag off, but I will continue working on fixes.
comment:16 by , 5 years ago
| Milestone: | 1.3 |
|---|
comment:17 by , 5 years ago
Related to #5327 (parsing Description into Title and Species), I now recommend putting Title and Species columns in that order in the factory default columns ("Standard") for PDB/NR results, like they already are for AlphaFold results. Resolution etc. would still be to the right of those.
Stll need to add a Rank column (1,2, ... in initial sort order by most significant E-value) on the far left for all results (AlphaFold, PDB, or NR).
To nitpick, Score and Resolution could be narrower and Title wider when the table initially appears, if that's possible... but maybe you're still working on that.
follow-up: 17 comment:18 by , 5 years ago
(Sorry for the zillions of messages, but can't tell if you were still planning to do something or whether it fell off the radar.) For AlphaFold results, recommend nuking "Chain Sequence ID" because it's both inconsistent and redundant, sometimes has a subset of the Name ( without the species suffix) and sometimes the same info as Gene of that same row. For PDB/NR results, "Chain Sequence ID" should be retitled UniProt because it's always a uniprot ID, as far as I can tell. Correct me if I'm wrong.
follow-up: 18 comment:19 by , 5 years ago
No worries, it's not off the radar, it's just not (imo) blocking 1.3 anymore. I'll be pushing fixes right up until the freeze.
comment:20 by , 5 years ago
I suggest changing the context menu wording. We try to use "selected" only to mean selected in the 3D structure (e.g. with green outlines). Sometimes I use "chosen" for rows highlighted in tables, or if it's something we want to keep short like a menu entry, sometimes omit either term and explain in documentation that it applies only to the chosen rows. Current wording: Load and Align Selections Show Selections in Sequence Viewer Suggested: Load Structures Show Sequence Alignment Other possibilities, can use if you like better: Load Structures of Chosen Hits Show Sequences of Chosen Hits Show MSA with Query
follow-up: 28 comment:22 by , 5 years ago
I'll try to summarize the column suggestions that are not yet done. Sorry it got so confusing above!
(1) From comment 8, for any kind of search add a Rank column in the Standard set on the far left. That was originally an "ID" column that I said should be nuked. But now I think it is useful, sorry for changing my mind!
(2) The remainder apply to PDB (and NR searches since they generally have PDB hits):
remove Keywords, Replaces, Status, and Structure ID columns
rename Chain Sequence ID to UniProt ID (for PDB/NR only; for AlphaFold we got rid of Chain Sequence ID)
rename Deposition Date to Date (remove Revision Date and Publish Date)
rename Structure Authors to Authors (remove Citation Authors)
rename Exp Method to Method
by , 5 years ago
| Attachment: | blast4hhb.png added |
|---|
blast results screenshot showing entities = polymers
comment:23 by , 5 years ago
Sorry another revision. Also the "# Entities" column should be removed:
After at least an hour of dorking around, I see that in blast results, "# Entities" is ALWAYS equal to "# Polymers" in contradiction to the discussion at the RCSB PDB of the meaning of "Entities" in this page:
<https://pdb101.rcsb.org/learn/guide-to-understanding-pdb-data/beginner%E2%80%99s-guide-to-pdb-structures-and-the-pdbx-mmcif-format>
I blasted PDB with their exact example protein 4hhb, which they say has 5 entities: alpha and beta subunits (2 copies each), water, phosphate, and heme. You can see in the attached screenshot, however, that in the results where it finds itself, # Entities and # Polymers are both given as 2. I cannot find any examples where these columns differ for the same hit and thus "# Entities" is completely redundant. (and possibly wrong)
comment:24 by , 5 years ago
The other slight possibility is that the code is mapping the input data to the output columns incorrectly and the #polymers in the input is being mapped to both #entities and #polymers in the output. But if that is not the case then nuking the #Entities oolumn would seem to be the way to go.
comment:25 by , 5 years ago
Looking at the code, I can see that '# Entities' comes from fetching the entry's polymer_entity_count and is therefore naturally identical to '# Polymers'. Either '# Entities' needs to fetch a different attribute, or we nuke '# Entities'. I lean towards the latter since I think "entities" is a confusing term for most users and we already make ligand info available in other columns.
comment:26 by , 5 years ago
The alternative is fetching nonpolymer_entity_count, which should be things like saccharides, but you'd want a different column name.
comment:28 by , 5 years ago
Replying to Elaine Meng:
I'll try to summarize the column suggestions that are not yet done. Sorry it got so confusing above!
(1) From comment 8, for any kind of search add a Rank column in the Standard set on the far left. That was originally an "ID" column that I said should be nuked. But now I think it is useful, sorry for changing my mind!
(2) The remainder apply to PDB (and NR searches since they generally have PDB hits):
remove Keywords, Replaces, Status, and Structure ID columns
rename Chain Sequence ID to UniProt ID (for PDB/NR only; for AlphaFold we got rid of Chain Sequence ID)
rename Deposition Date to Date (remove Revision Date and Publish Date)
rename Structure Authors to Authors (remove Citation Authors)
rename Exp Method to Method
Should be fixed by this commit. I accomplished (1) by enabling the row numbers for ItemTable in ui/widgets/item_table.py -- I just set the visibility of the numbers to False in other bundles that used the ItemTable class. As a two-for-one, this fix also fixed a bug that has long plagued ItemTables: the five pixel empty column to the left of the real data. I'll post a before and after screenshot.
by , 5 years ago
| Attachment: | Screen Shot 2021-10-06 at 6.50.16 PM.png added |
|---|
No small empty column on the left
by , 5 years ago
| Attachment: | Screen Shot 2021-10-06 at 6.24.12 PM.png added |
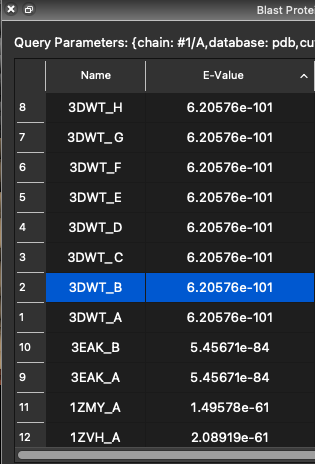
|---|
Using row numbers as ranks. I'm not sure if the problem of ties resulting in misordering of the numbers would be better with a "Rank" column
follow-up: 27 comment:29 by , 5 years ago
Good point. Do you have any ideas for a name for this column? I thought "ID" was weird, but if you two think it's OK I could live with it. Maybe there is something better.
comment:30 by , 5 years ago
Eric suggests "#" or "Hit #" ... either of those is fine with me. What do you think?
comment:32 by , 5 years ago
Thanks, I see Hit #! Next suggestion is that it should be on the far left in the table and included in the Standard (factory default) set of columns.
comment:33 by , 5 years ago
Oh, and start at 1, not zero. It's also wider than need be but I assume that will be worked on along with other column widths eventually.
follow-up: 29 comment:34 by , 5 years ago
I've implemented both of these; they should be in the daily build tomorrow!
follow-up: 30 comment:35 by , 5 years ago
| Resolution: | → fixed |
|---|---|
| Status: | assigned → closed |
Looks like the last thing to do is the column widths. I spun that off into another ticket. I think for my own mental organization purposes, we should open new tickets for further changes.
(It's a checkbox)
1
1a
1b
2
2b (as part of #5267)
3
4
5a
5bProhibitively complex, I think.6: 1670e2 and 2e6a1e
7
8
Revisions:
Sort by smallest to highest evalue
Possibly include column index