Opened 5 years ago
Closed 5 years ago
#5216 closed defect (fixed)
need better parsing of BlastProtein AlphaFold results
| Reported by: | Elaine Meng | Owned by: | Zach Pearson |
|---|---|---|---|
| Priority: | moderate | Milestone: | 1.3 |
| Component: | Sequence | Version: | |
| Keywords: | Cc: | Tom Goddard | |
| Blocked By: | Blocking: | ||
| Notify when closed: | Platform: | all | |
| Project: | ChimeraX |
Description
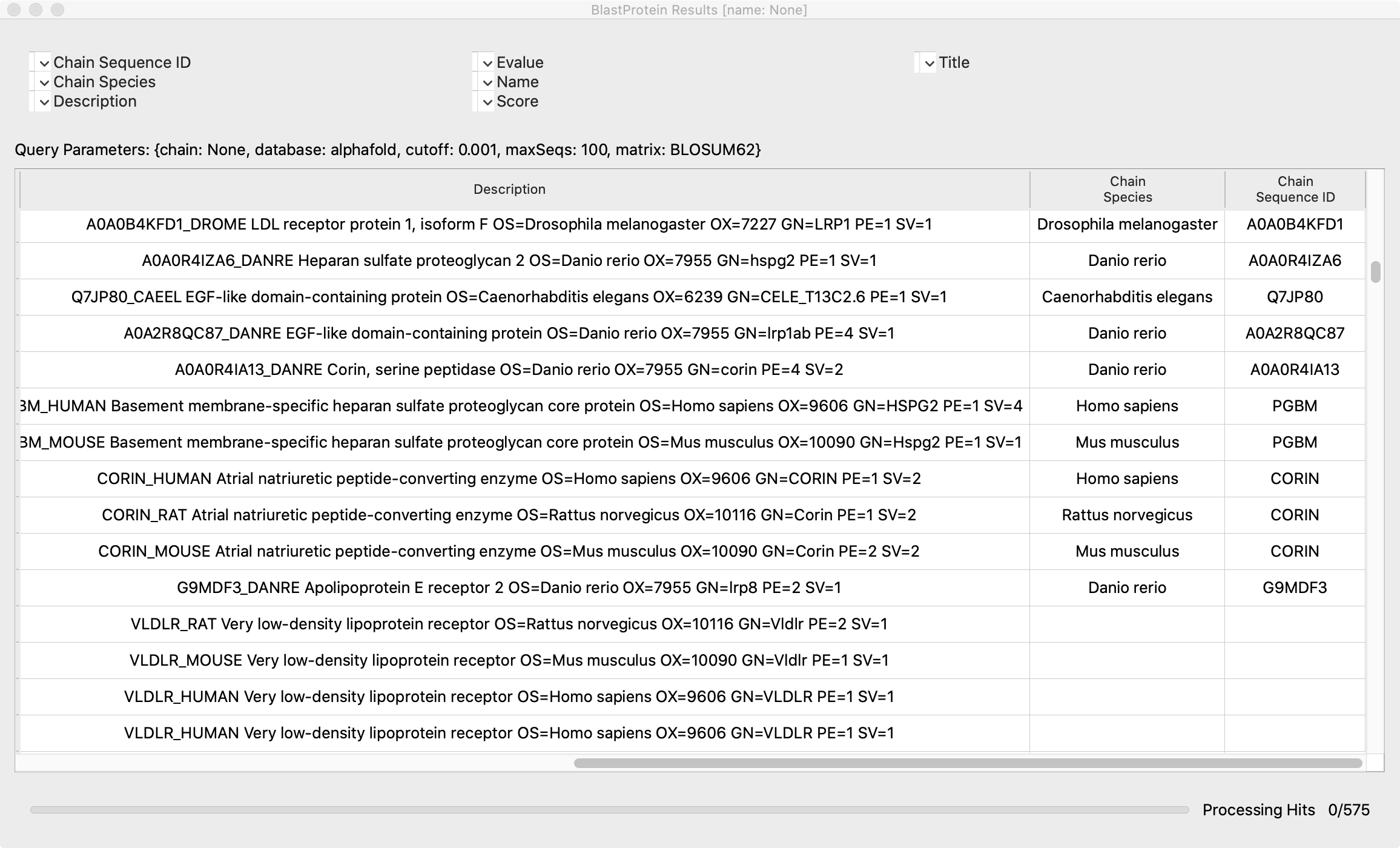
Often some of the column values are blank but I believe that to be a bug because the Description field contains many of the other fields' values so I can see that the values do exist. Also sometimes the Chain Sequence ID is the gene name and sometimes it is not, which I also suspect to be a bug. Both of these problems could well be due to the inconsistent format of the database, but suggests we need to posprocess the Description field to set them right.
For example "alphafold search ldlr_human" see results in screenshot. (I wish I could copy text and paste, but it does not allow that).
Description field contains:
Name Title OS=Species OX=L GN=text PE=N SV=M
Many of the hits show a title and species in the Description field but have blank Title and Species columns.
GN is apparently gene name. No idea what OX, PE, and SV are. At first I thought OX was length but I can see it is way too high for that. (Too bad, it would be useful if there were a column for length.)
Currently the Blast output dialog has inconsistent values in the Chain Sequence ID field. Sometimes it is gene name, sometimes it is the part of the Name (UniProt Name) preceding the underscore, sometimes blank. Maybe we should get rid of Chain Sequence ID and add a Gene Name column with the GN value from the Description. It usually looks reasonable but is occasionally weird, e.g. for hit highlighted in the second screen shot.
Attachments (2)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Change History (12)
by , 5 years ago
| Attachment: | blast-alphafold-ldlr-human.png added |
|---|
by , 5 years ago
| Attachment: | Screen Shot 2021-09-13 at 12.15.39 PM.png added |
|---|
comment:2 by , 5 years ago
| Milestone: | → 1.3 |
|---|
follow-up: 1 comment:3 by , 5 years ago
I'm somewhat changing my mind on this one because I see that there is a similar issue with sequence-only hits (based on blasting NR with Chimera... I haven't been able to get it to work in ChimeraX). Namely for those Description includes both a title and a species, but Title and Species themselves are blank.
I'm working on what the default columns should be which is why I'm trying to understand all their contents. So I may have to simply suggest Description as a default column instead of Title and Species. Although the latter would be nice as they'd be independently sortable, it may simply be too much work at this point to try to fill them all in, especially if all the sequence-only hits from NR (and UniRef if that's exposed) are going to have a similar issue.
comment:4 by , 5 years ago
| Priority: | high → moderate |
|---|
comment:5 by , 5 years ago
Comparing the results from an AlphaFold BLAST hit
"title": "tr|Q8I1R6|Q8I1R6_PLAF7 Bifunctional dihydrofolate reductase-thymidylate synthase OS=Plasmodium falciparum (isolate 3D7) OX=36329 GN=PF3D7_0417200 PE=3 SV=1"
to its Uniprot entry, I think OX is the taxonomic identifier from NCBI (Ctrl/Cmd+F "taxonomic id").
I also have a feeling that PE is predicted error. Still no clue what SV stands for, though.
I can have this in tomorrow's daily build. I think after we parse the description field we can delete it, since all of its data is going to go into other columns.
comment:6 by , 5 years ago
Maybe it's not predicted error: https://alphafold.ebi.ac.uk/entry/Q8I1R6 it doesn't look like something that can be reduced to an integer. If they're not useful, we can just not show them. There's no federal law that says all data must be used. :p
comment:7 by , 5 years ago
In the AlphaFold results I looked at, when the Species column was populated, it matched what was in the OS value of Description, so that would definitely be good to parse out, along with the Title. I also saw in previous NR results that sequence-only hits can (or always?) have both title and species in the Description field, but blank Title and Species columns, so a similar parsing would be desirable there. However, the Description format is different, e.g. species at the end in square brackets, no "OS=" Are you also suggesting to add a TaxID column for the OX value of AlphaFold results? Sounds OK to me. Could also do it for those other values if we figure out what they mean and it might be useful, or just drop them if not, as you said in your comment. If you do parse everything from Description and omit Description, then my "initial default columns" suggestions in #5228 would change, of course. I'd recommend Title + Species instead of Description, if that happens.
follow-up: 7 comment:9 by , 5 years ago
These FASTA files come from the UniProt database. Googling uniprot fasta description fields explains them
comment:10 by , 5 years ago
| Resolution: | → fixed |
|---|---|
| Status: | assigned → closed |
Thank you!
This should do it. Parsed out all of the info from the raw description and sent it to the appropriate column.