Opened 3 years ago
Closed 3 years ago
#8499 closed defect (fixed)
Collate details about DICOM collections from series
| Reported by: | Zach Pearson | Owned by: | Zach Pearson |
|---|---|---|---|
| Priority: | moderate | Milestone: | 1.6 |
| Component: | DICOM | Version: | |
| Keywords: | Cc: | Elaine Meng | |
| Blocked By: | Blocking: | ||
| Notify when closed: | Platform: | all | |
| Project: | ChimeraX |
Description
The nbia api is much more detailed at the study level than the collections level, or the data can be scraped at the same time as links are scraped.
Attachments (1)
{kind=link}
Change History (9)
comment:1 by , 3 years ago
follow-up: 2 comment:2 by , 3 years ago
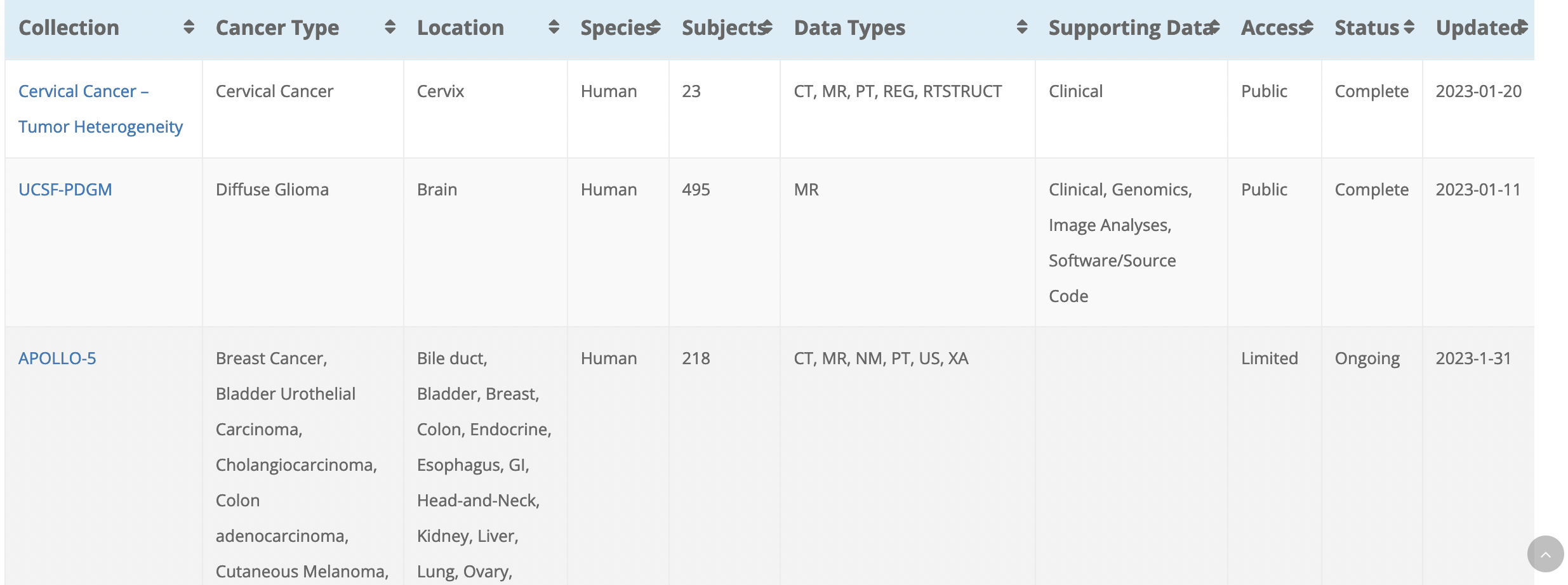
Hi Zach, If it's not too many things, I would vote for Collection (sans "Name") Cancer Type (sometimes redundant with Location but often has more info) Species (I saw a lot of dogs and rodents when I was browsing around) Subjects (since dogs and rodents aren't really patients? But I'm OK with "Patients" too if you preferred it since that is DICOM terminology) Modality (or "Data Type" or "Data Types" ... whichever you like, really, and Modality is reasonable since it's DICOM terminology) The image is a screenshot of the Browse Collections page at the TCIA website:

comment:3 by , 3 years ago
Collection, Species, Subjects, and Modality are possible today, but I think the closest I can get to cancer type without asking them to modify their API (which I can do!) is location (body part).
Is that acceptable?
comment:4 by , 3 years ago
Hi Zach, Oh, I thought all of the columns shown in their browse-database page were equally available. Strange, seems like "cancer type" is of primary importance (and they also must think so since it is the first column they show after Collection)! However, I understand if you only have access to Location, we can use that instead unless they improve their API. Elaine
follow-up: 4 comment:5 by , 3 years ago
I opened a pull request on the library we're using to access TCIA data. Their API client was missing an endpoint that would reduce the number of API calls we need to make per-collection from 4 down to 2. I wanted to get this done because the individual requests can take a long time. Once it's merged, I'll finish this ticket.
comment:6 by , 3 years ago
| Status: | assigned → closed |
|---|
I have this working, but it's slow to download. Each collection (there are 114 of them) requires a separate request to download information, then we have to parse it to get it into place. I added a progress message because it takes about two minutes and I started to worry it wasn't doing anything. If this feels agonizingly slow reopen this ticket and I'll work on caching the results of one download in CxServices and set up a job to periodically retrieve new data. I'll push the changes for tomorrow's daily build.
comment:7 by , 3 years ago
| Status: | closed → reopened |
|---|
comment:8 by , 3 years ago
| Resolution: | → fixed |
|---|---|
| Status: | reopened → closed |
What do you think of: Collection Name, Patients, Locations, Modalities as the columns for the first table in the tool?