

 home
overview
research
resources
outreach & training
outreach & training
visitors center
visitors center
search
search
home
overview
research
resources
outreach & training
outreach & training
visitors center
visitors center
search
search
home
overview
research
resources
outreach & training
outreach & training
visitors center
visitors center
search
search
home
overview
research
resources
outreach & training
outreach & training
visitors center
visitors center
search
search

John A. Gerlt¹, Steven Almo², Frank Raushel³, Andrej Sali4, Brian Shoichet4, Matthew Jacobson4, and Patricia C. Babbitt5
¹ University of Illinois
² Albert Einstein University
³ Texas A&M University
4University of California, San Francisco
5
Resource for Biocomputing, Visualization, and Informatics
University of California, San Francisco
Introduction
The enolase and amidohydrolase (AH) superfamilies are recognized as paradigms for understanding how 1) protein structure delivers enzymatic function; and 2) Nature uses these strategies for the divergent evolution of catalysts for new reactions (Gerlt, 2001; Gerlt, 2003). These superfamilies share the (β/α)8-barrel fold that is found in ≥10% of structures deposited in Protein Data Bank. The most recent SCOP database (release 1.69, July 2005) describes 31 functionally diverse superfamilies possessing the (β/α)8-barrel fold revealing a remarkably diverse array of chemical reactions. A focus on understanding how sequence and structure determine substrate specificity in the enolase and AH superfamilies, in particular, and those enzymes sharing (β/α)8-barrel fold, in general, should have immediate relevance to assigning functions to many proteins of unknown functions, including those structurally characterized by the Protein Structural Initiative (PSI).The members of the AH superfamily contain a single domain with the (β/α)8-barrel fold. The members of the enolase superfamily contain two domains, one with the (β/α)8-barrel fold and a second formed by segments from the N- and C-terminal segments of the linear sequence. In both superfamilies, functional groups located at the C-terminal ends of β-strands in the (β/α)8-barrel provide ligands for essential divalent metal ions that direct the common chemistry that is delivered by the various members of each superfamily. In the AH superfamily, a metal ion (in a mono- or binuclear center, depending on the structure of the substrate) delivers a hydroxide nucleophile to the substrate, thereby accomplishing a hydrolysis reaction. In the enolase superfamily, the metal ion stabilizes a dianionic enediolate intermediate generated by proton abstraction from the carbon adjacent to the carboxylate group of the substrate by an active site base; the intermediate is directed to product by an active site acid. In both superfamilies, the reactions are unimolecular (excluding the water cosubstrate in reactions catalyzed by the AH superfamily), so prediction of substrate specificity is sufficient for functional assignment.
This program project focuses on deciphering the structural determinants of specificity for both of these superfamilies. Together, they provide a good test-bed for this project because the structural details by which substrate specificity is delivered are not conserved in the two superfamilies despite their both belonging to the same fold class. In the AH superfamily, specificity is determined by the loops at the ends of the β-strands in the (β/α)8-barrel; in the available structures, these loops do not undergo significant conformational changes when the ligand binds in the active site. In the enolase superfamily, the active sites are located at the interface between a "capping domain" and a (β/α)8-barrel domain, with specificity determined by two loops in the capping domain as well as residues at the end of the eighth β-strand in the (β/α)8-barrel domain; in the available structures, the loops in the capping domain often, but not always, undergo conformational changes when the ligand binds in the active site, thereby providing an enhanced challenge for the prediction of ligand specificity. The complementarity of these systems is essential for devising an integrated functional, structural, and computational strategy for predicting their ligands. We expect that this strategy will be generally applicable even to proteins that do not share the (β/α)8-barrel fold.
In both superfamilies, the structure/function studies reveal that the chemistry is "hard-wired" by the functional groups at the ends of the β-strands in the (β/α)8-barrels; the overall reactions are determined by the identity of the substrate that is directed to bind in the active site (Schmidt, 2003). The recognition that each target superfamily delivers a characteristic chemistry simplifies the problem of assigning function-deciphering the specificity programmed by the sequence and structure will be sufficient to assign function. This Program Project proposed, for the first time, to integrate functional and structural enzymology with computational biology to enable prediction of the specific functions of enzymes. To achieve these goals, the overall Program Project is composed of three component projects: 1) preparative, functional, and structural studies of members of the enolase superfamily (Gerlt, P.I.); 2) preparative, functional, and structural studies of members of the AH superfamily (Raushel, P.I); and 3) computational studies of members of both superfamilies involving bioinformatics analyses, homology modeling, high resolution modeling of specificity-determining loops; and molecular docking of potential ligands (Babbitt, P.I.; Sali, Shoichet, and Jacobson, Coinvestigators).
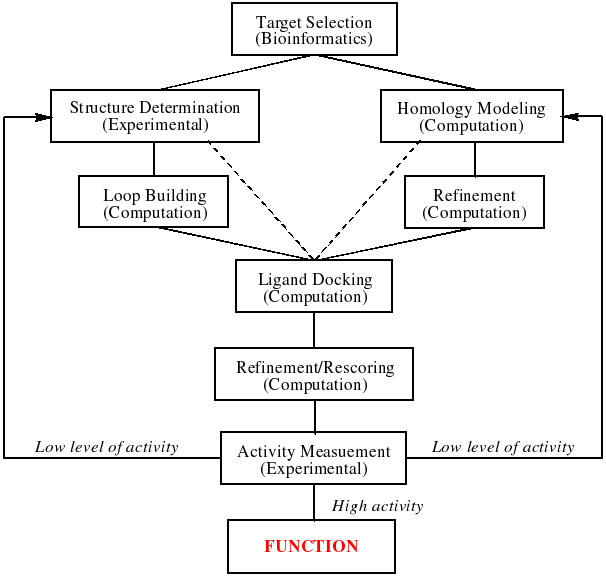
By harnessing the power of bioinformatics, comparative modeling of protein structures, and docking of ligand libraries to enzyme structures, these investigations will enable both high throughput analysis for the inference of function and aid experimental functional determination by predicting substrate specificity. Outcomes of this research extend well beyond functional inference for the 1000+ members of the enolase superfamily and 6000+ members of the AH superfamily that have been identified so far. Thus, using these superfamilies as model systems we hope to design and validate a general approach to addressing the very difficult problem of deducing the specific functions of enzymes. This is to be achieved through an iterative cycle of experimental and computational research as shown in the figure below. Specifically, we expect that new insights into the molecular strategies by which substrate specificity is determined by these enzymes that share the (β/α)8-barrel will be transferable to 1) prediction of ligand specificity for functionally unknown proteins in this and other folds; and 2) (re)design of substrate specificities in the functionally diverse (β/α)8-barrel template to enable the syntheses of novel and useful intermediates for biomedical applications.
Progress
In the first two years of the project, progress was made by the experimental groups in generating dozens of new clones of unknown function for functional testing and over a dozen structures have been solved in the laboratory of Co-Investigator Steven Almo (for the enolase superfamily, deposited PDB structures are 1rvk, 1tez, 1tkk, 1tzz, 1wwe, 1wue, 1yey, 2gdq; for the AH superfamily, deposited pdb structures are 1xwy, 1zzm, 1yix, 1ymy). More recently, the New York Structural Genomics Consortium has agreed to generate clones and structures for dozens more of the members of both the enolase and AH superfamilies whose functions are unknown. Guidance for choosing targets for structural characterization was provided by the Babbitt and Sali groups, who used bioinformatics, including careful phylogenetic analysis, and comparative structural modeling. This effort has given us a good idea of which sequences are most likely to represent additional new functions.Another important outcome of this research to date is the work done in the Jacobson and Shoichet labs in collaboration with the experimental labs to develop and apply in silico docking methods to interrogate libraries of metabolites to suggest potential functions for uncharacterized members of the enolase (Kalyanaraman, 2005) and AH superfamilies (Irwin, 2005). While these approaches have not yet resulted in published confirmation of new functions, they have made progress in the development of the methodology that will be required to achieve this goal.
Collaboration with the RBVI
This Program Project emerged from a more than decade-long collaboration between the Gerlt and Babbitt labs in attempting to understand the structural strategies nature has used in evolving many different functions from the enolase and other superfamily scaffolds. Working together, our labs have published 12 collaborative papers in this area, including several major ones that laid out in detail the theory for structure-function relationships in mechanistically diverse enzyme superfamilies (Babbitt, 1997; Babbitt, 2000; Gerlt, 2001). This body of work formed the theoretical foundation for the initial development of the SFLD. Prior to the funding of this Program Project, the Gerlt and Babbitt labs worked together to curate three of the founder SFLD superfamilies, the enolase, amidohydrolase, and crotonase superfamilies. Following the funding of the Program Project described here, the SFLD took on a major role in supporting both the experimental and bioinformatic analyses required of this research.Collaboration with the RBVI to achieve the goals of this Program Project are now focused on the use of the SFLD to aid in the management of data developed across the components of the project, including serving as the formal archive of sequence, structure, and function information for the enolase and AH superfamilies. An associated database, EnSpec, provides tracking information to all of the collaborators regarding progress in characterizing each protein under study.
In addition to work focused on the SFLD, we face difficult problems in clustering the many divergent sequences that are members of these superfamilies, most of which are of unknown function. From the preliminary results of the RBVI research project, "Integrated Visualization and Analysis of Biological Context," in its applications to protein superfamily analysis, this project could be of great value in helping us develop hypotheses about the functions of the many families in our superfamilies. Having a tool that experimental scientists such as ourselves, who are not sophisticated in bioinformatics, can easily use to explore these sequence-structure-function relationships using different Blast E-value cut-offs, for example, would be of huge value. Implementing these tools for use in the SFLD is especially attractive to us, since this gives us simple, easy-to-use access to capabilities that are beyond the skills of our labs to manage without the help of the RBVI.
References:
- Babbitt, P.C. and Gerlt, J.A., "Understanding enzyme superfamilies: Chemistry as the fundamental determinant in the evolution of new catalytic activities," Jour. Biol. Chem., 1997. 272: p. 30591-30594.
- Babbitt, P.C. and Gerlt, J.A., "New functions from old scaffolds: how nature reengineers enzymes for new functions," Adv Protein Chem, 2000. 55: p. 1-28.
- Gerlt, J.A. and P.C. Babbitt, "DIVERGENT EVOLUTION OF ENZYMATIC FUNCTION: Mechanistically Diverse Superfamilies and Functionally Distinct Suprafamilies," Annu Rev Biochem, 2001. 70: p. 209-246.
- Gerlt, J.A. and F.M. Raushel, "Evolution of function in (beta/alpha)(8)-barrel enzymes," Curr Opin Chem Biol, 2003. 7(2): p. 252-64.
- Irwin, J.J., Raushel, F.M., and Shoichet, B.K., "Virtual screening against metalloenzymes for inhibitors and substrates," Biochemistry, 2005. 44(37): p. 12316-28.
- Kalyanaraman, C., Bernacki, K., and Jacobson, M.P., "Virtual screening against highly charged active sites: identifying substrates of alpha-beta barrel enzymes," Biochemistry, 2005. 44(6): p. 2059-71.
- Schmidt, D.M., Mundorff, E.C., Dojka, M., Bermudez, E., Ness, J.E., Govindarajan, S., Babbitt, P.C., Minshull, J., and Gerlt, J.A., "Evolutionary potential of (beta/alpha)8-barrels: functional promiscuity produced by single substitutions in the enolase superfamily," Biochemistry, 2003. 42(28): p. 8387-93.
Laboratory Overview | Research | Outreach & Training | Available Resources | Visitors Center | Search